Greedy Algorithms Tutorial
Greedy algorithms are a class of algorithms that make locally optimal choices at each step with the hope of finding a global optimum solution.
I. Greedy Algorithms
Greedy is an algorithmic paradigm that builds up a solution piece by piece, always choosing the next piece that offers the most obvious and immediate benefit. Greedy algorithms are used for optimization problems.
An optimization problem can be solved using Greedy if the problem has the following property:
- At every step, we can make a choice that looks best at the moment, and we get the optimal solution to the complete problem.
- Some popular Greedy Algorithms are Fractional Knapsack, Dijkstra’s algorithm, Kruskal’s algorithm, Huffman coding and Prim’s Algorithm
- Also used to get an approximation for Hard optimization problems. For example, the Traveling Salesman Problem is an NP-Hard problem. A Greedy choice for this problem is to pick the nearest unvisited city from the current city at every step. These solutions don’t always produce the best optimal solution but can be used to get an approximately optimal solution.
However, it’s important to note that not all problems are suitable for greedy algorithms. They work best when the problem exhibits the following properties:
- Greedy Choice Property: The optimal solution can be constructed by making the best local choice at each step.
- Optimal Substructure: The optimal solution to the problem contains the optimal solutions to its sub-problems.
Greedy Algorithm solve optimization problems by making the best local choice at each step in the hope of finding the global optimum. It’s like taking the best option available at each moment, hoping it will lead to the best overall outcome.
Here’s how it works:
- Start with the initial state of the problem.
- Consider all the options available at that specific moment.
- Choose the option that seems best at that moment, regardless of future consequences. This is the “greedy” part - you take the best option available now, even if it might not be the best in the long run.
- Move to the new state based on your chosen option. This becomes your new starting point for the next iteration.
- Repeat steps 2-4 until you reach the goal state or no further progress is possible.
Example:
Let’s say you have a set of coins with values [1, 2, 5, 10] and you need to give minimum number of coin to someone change for 39.
The greedy algorithm for making change would work as follows:
- Step-1: Start with the largest coin value that is less than or equal to the amount to be changed. In this case, the largest coin less than or equal to 39 is 10.
- Step- 2: Subtract the largest coin value from the amount to be changed, and add the coin to the solution. In this case, subtracting 10 from 39 gives 29, and we add one 10-coin to the solution.
- Repeat steps 1 and 2 until the amount to be changed becomes 0.
Below is the illustration of above example:
Step 1: We need to make change for 39 using couns of denominations {1, 2, 5, 10} using the fewest number of coins.

Step 2: Start with the highest denomination (10). Since greedy algorithms works by taking the largest coin possible fist, we start with the coin of denomination 10.

Step 3: Now take the next highest denimonation (5).
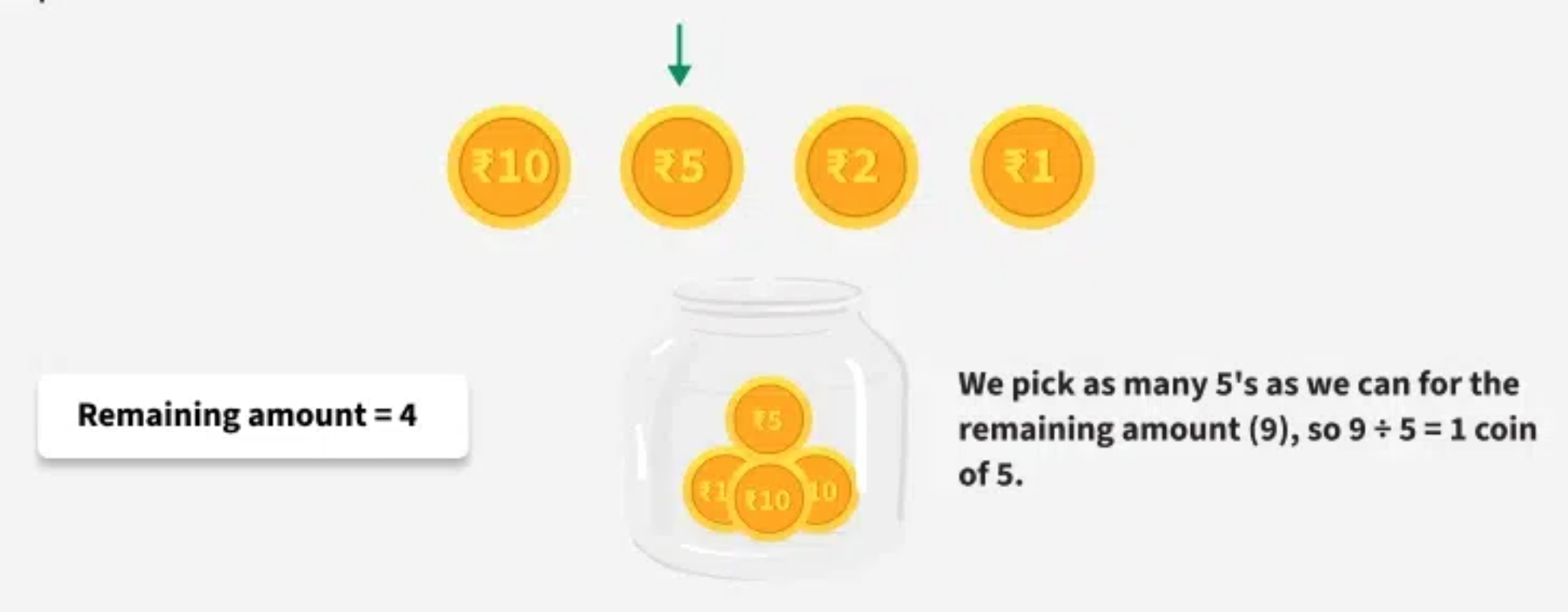
Now thake the next highest denomination (2)

Step 5: Successfully make the target sum (39) using a total of 6 coins:
\[3 \times 10 + 1 \times 5 + 2 \times 2 = 30\]
Code demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# Python Program to find the minimum number of coins
# to construct a given amount using greedy approach
def minCoins(coins, amount):
n = len(coins)
coins.sort()
res = 0
# Start from the coin with highest denomination
for i in range(n - 1, -1, -1):
if amount >= coins[i]:
# Find the maximum number of ith coin we can use
cnt = amount // coins[i]
# Add the count to result
res += cnt
# Subtract the corresponding amount from the total amount
amount -= cnt * coins[i]
# Break if there is no amount left
if amount == 0:
break
return res
if __name__ == "__main__":
coins = [5, 2, 10, 1]
amount = 39
print(minCoins(coins, amount))
II. Greedy Algorithms General Structure
A greedy algorithm solves problems by making the best choice at each step. Instead of looking at all possible solutions, it focuses on the option that seems best right now.
Problem structure:
Most of the problems where greedy algorithms work follow these two properties:
- Greedy Choice Property:- This property states that choosing the best possible option at each step will lead to the best overall solution. If this is not true, a greedy approach may not work.
- Optimal Substructure:- This means that you can break the problem down into smaller parts, and solving these smaller parts by making greedy choices helps solve the overall problem.
Some algorithms
Sorting
Job Sequencing: In order to maximize profits, we prioritize jobs with higher profits. So we sort them in descending order based on profit. For each job, we try to schedule it as late as possible within its deadline to leave earlier slots open for other jobs with closer deadlines.
Activity Selection: To maximize the number of non-overlapping activities, we prioritize activities that end earlier, which helps us to select more activities. Therefore, we sort them based on their end times in ascending order. Then, we select the first activity and continue adding subsequent activities that start after the previous one has ended.
Disjoint Intervals: The approach for this problem is exactly similar to previous one, we sort the intervals based on their start or end times in ascending order. Then, select the first interval and continue adding next intervals that start after the previous one ends.
Fractional Knapsack: The basic idea is to calculate the ratio profit/weight for each item and sort the item on the basis of this ratio. Then take the item with the highest ratio and add them as much as we can (can be the whole element or a fraction of it).
Kruskal Algorithm: To find the Minimum Spanning Tree (MST), we prioritize edges with the smallest weights to minimize the overall cost. We start by sorting all the edges in ascending order based on their weights. Then, we iteratively add edges to the MST while ensuring that adding an edge does not form a cycle.
Using Priority Queue or Heaps
Dijkstra Algorithm: To find the shortest path from a source node to all other nodes in a graph, we prioritize nodes based on the smallest distance from the source node. We begin by initializing the distances and using a min-priority queue. In each iteration, we extract the node with the minimum distance from the priority queue and update the distances of its neighboring nodes. This process continues until all nodes have been processed, ensuring that we find the shortest paths efficiently.
Connect N ropes: In this problem, the lengths of the ropes picked first are counted multiple times in the total cost. Therefore, the strategy is to connect the two smallest ropes at each step and repeat the process for the remaining ropes. To implement this, we use a min-heap to store all the ropes. In each operation, we extract the top two elements from the heap, add their lengths, and then insert the sum back into the heap. We continue this process until only one rope remains.
Huffman Encoding: To compress data efficiently, we assign shorter codes to more frequent characters and longer codes to less frequent ones. We start by creating a min-heap that contains all characters and their frequencies. In each iteration, we extract the two nodes with the smallest frequencies, combine them into a new node, and insert this new node back into the heap. This process continues until there is only one node left in the heap.
III. Standard Greedy Algorithms
1. Huffman Coding
Huffman coding is a lossless data compression algorithm. The idea is to assign variable-length codes to input characters, lengths of the assigned codes are based on the frequencies of corresponding characters.
The variable-length codes assigned to input characters are Prefix Codes, means the codes (bit sequences) are assigned in such a way that the code assigned to one character is not the prefix of code assigned to any other character. This is how Huffman Coding makes sure that there is no ambiguity when decoding the generated bitstream. Let us understand prefix codes with a counter example. Let there be four characters a, b, c and d, and their corresponding variable length codes be 00, 01, 0 and 1. This coding leads to ambiguity because code assigned to c is the prefix of codes assigned to a and b. If the compressed bit stream is 0001, the de-compressed output may be “cccd” or “ccb” or “acd” or “ab”.
There are mainly two major parts in Huffman Coding
- Build a Huffman Tree from input characters.
- Traverse the Huffman Tree and assign codes to characters.
Steps to build Huffman Tree This algorithm builds a tree in bottom up manner using a priority queue (or heap). Input is an array of unique characters along with their frequency of occurrences and output is Huffman Tree.
- Step 1: Create a leaf node for each unique character and build a min heap of all leaf nodes (Min Heap is used as a priority queue. The value of frequency field is used to compare two nodes in min heap. Initially, the least frequent character is at root)
- Step 2: Extract two nodes with the minimum frequency from the min heap.
- Step 3: Create a new internal node with a frequency equal to the sum of the two nodes frequencies. Make the first extracted node as its left child and the other extracted node as its right child. Add this node to the min heap.
- Step 4: Repeat Steps#2 and #3 until the heap contains only one node. The remaining node is the root node and the tree is complete.
Let us understand the algorithm with an example:
1
2
3
4
5
6
7
character Frequency
a 5
b 9
c 12
d 13
e 16
f 45
- Step 1. Build a min heap that contains 6 nodes where each node represents root of a tree with single node.
- Step 2 Extract two minimum frequency nodes from min heap. Add a new internal node with frequency 5 + 9 = 14.
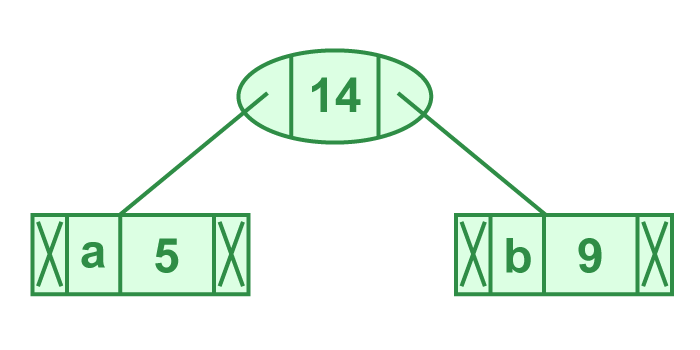
Now min heap contains 5 nodes where 4 nodes are roots of trees with single element each, and one heap node is root of tree with 3 elements
1
2
3
4
5
6
character Frequency
c 12
d 13
Internal Node 14
e 16
f 45
- Step 3: Extract two minimum frequency nodes from heap. Add a new internal node with frequency 12 + 13 = 25
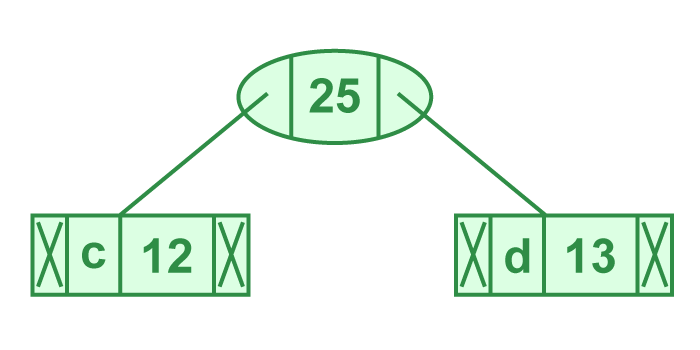
Now min heap contains 4 nodes where 2 nodes are roots of trees with single element each, and two heap nodes are root of tree with more than one nodes
1
2
3
4
5
character Frequency
Internal Node 14
e 16
Internal Node 25
f 45
- Step 4: Extract two minimum frequency nodes. Add a new internal node with frequency 14 + 16 = 30
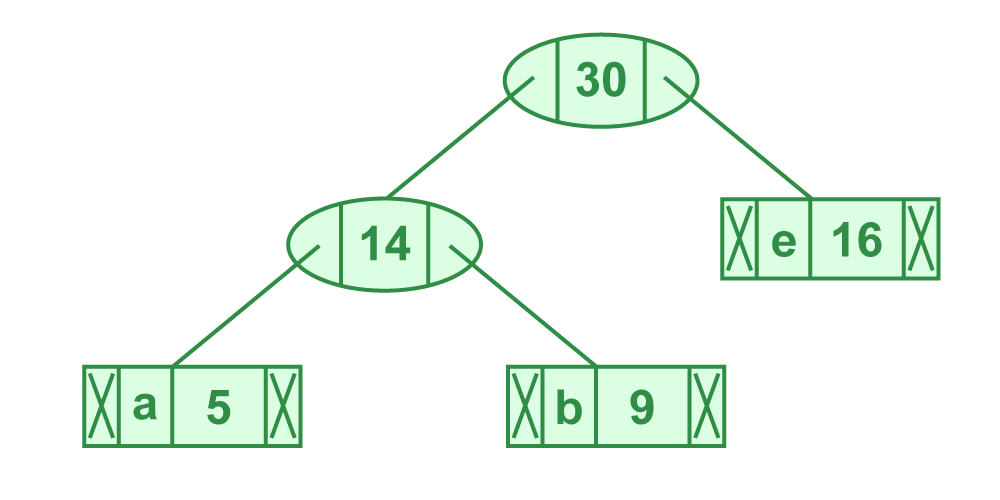
Now min heap contains 3 nodes.
1
2
3
4
character Frequency
Internal Node 25
Internal Node 30
f 45
- Step 5: Extract two minimum frequency nodes. Add a new internal node with frequency 25 + 30 = 55
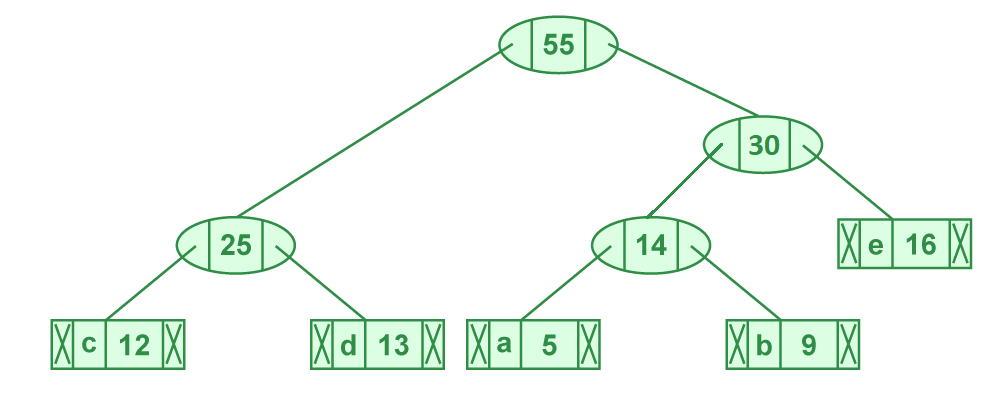
Now min heap contains 2 nodes.
1
2
3
character Frequency
f 45
Internal Node 55
- Step 6: Extract two minimum frequency nodes. Add a new internal node with frequency 45 + 55 = 100
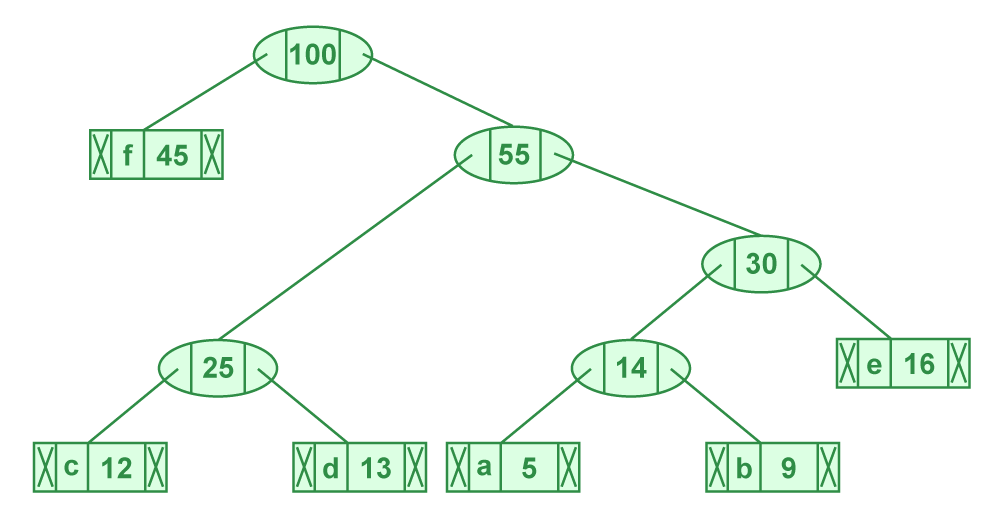
Now min heap contains only one node.
1
2
character Frequency
Internal Node 100
Steps to print codes from Huffman Tree:
Traverse the tree formed starting from the root. Maintain an auxiliary array. While moving to the left child, write 0 to the array. While moving to the right child, write 1 to the array. Print the array when a leaf node is encountered.
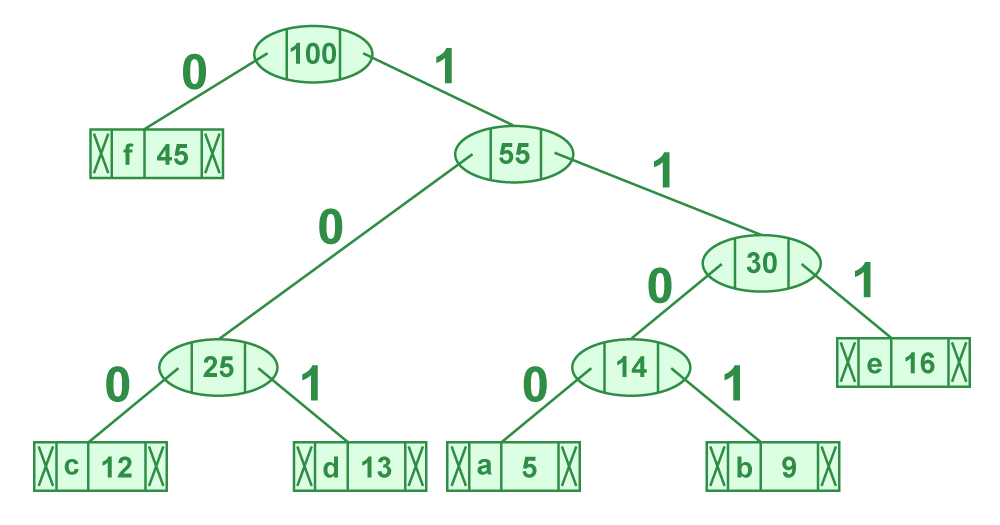
The codes are as follows:
1
2
3
4
5
6
7
character code-word
f 0
c 100
d 101
a 1100
b 1101
e 111
Code demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# Python program for the above approach:
import heapq
# Class to represent huffman tree
class Node:
def __init__(self, x):
self.data = x
self.left = None
self.right = None
def __lt__(self, other):
return self.data < other.data
# Function to traverse tree in preorder
# manner and push the huffman representation
# of each character.
def preOrder(root, ans, curr):
if root is None:
return
# Leaf node represents a character.
if root.left is None and root.right is None:
ans.append(curr)
return
preOrder(root.left, ans, curr + '0')
preOrder(root.right, ans, curr + '1')
def huffmanCodes(s, freq):
# Code here
n = len(s)
# Min heap for node class.
pq = []
for i in range(n):
tmp = Node(freq[i])
heapq.heappush(pq, tmp)
# Construct huffman tree.
while len(pq) >= 2:
# Left node
l = heapq.heappop(pq)
# Right node
r = heapq.heappop(pq)
newNode = Node(l.data + r.data)
newNode.left = l
newNode.right = r
heapq.heappush(pq, newNode)
root = heapq.heappop(pq)
ans = []
preOrder(root, ans, "")
return ans
if __name__ == "__main__":
s = "abcdef"
freq = [5, 9, 12, 13, 16, 45]
ans = huffmanCodes(s, freq)
for code in ans:
print(code, end=" ")
2. Huffman Decoding
Examples:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Input Data: ShandyDemo
Frequencies: S: 1, h: 1, a: 1, n: 1, d: 1, y: 1, D: 1, e: 1, m: 1, o: 1
Encoded Data: 0000010100111001011100110111101111
Huffman Tree: '#' is the special character used for internal nodes as character field is not needed for internal nodes.
#(10)
/ \
#(4) #(6)
/ \ / \
#(2) #(2) #(2) #(4)
/ \ / \ / \ / \
S(1) h(1) a(1) n(1) d(1) y(1) D(1) #(2)
/ \
e(1) #(2)
/ \
m(1) o(1)
Code of 'S' is '000', code of 'h' is '001', ..
Decoded Data: ShandyDemo
Follow the below steps to solve the problem:
Note: To decode the encoded data we require the Huffman tree. We iterate through the binary encoded data. To find character corresponding to current bits, we use the following simple steps:
- We start from the root and do the following until a leaf is found.
- If the current bit is 0, we move to the left node of the tree.
- If the bit is 1, we move to right node of the tree.
- If during the traversal, we encounter a leaf node, we print the character of that particular leaf node and then again continue the iteration of the encoded data starting from step 1.
The below code takes a string as input, encodes it, and saves it in a variable encoded string. Then it decodes it and prints the original string.
Below is the implementation of the above approach:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
import heapq
from collections import defaultdict
# to map each character its huffman value
codes = {}
# To store the frequency of character of the input data
freq = defaultdict(int)
# A Huffman tree node
class MinHeapNode:
def __init__(self, data, freq):
self.left = None
self.right = None
self.data = data
self.freq = freq
def __lt__(self, other):
return self.freq < other.freq
# utility function to print characters along with
# there huffman value
def printCodes(root, str):
if root is None:
return
if root.data != '$':
print(root.data, ":", str)
printCodes(root.left, str + "0")
printCodes(root.right, str + "1")
# utility function to store characters along with
# there huffman value in a hash table
def storeCodes(root, str):
if root is None:
return
if root.data != '$':
codes[root.data] = str
storeCodes(root.left, str + "0")
storeCodes(root.right, str + "1")
# function to build the Huffman tree and store it
# in minHeap
def HuffmanCodes(size):
global minHeap
for key in freq:
minHeap.append(MinHeapNode(key, freq[key]))
heapq.heapify(minHeap)
while len(minHeap) != 1:
left = heapq.heappop(minHeap)
right = heapq.heappop(minHeap)
top = MinHeapNode('$', left.freq + right.freq)
top.left = left
top.right = right
heapq.heappush(minHeap, top)
storeCodes(minHeap[0], "")
# utility function to store map each character with its
# frequency in input string
def calcFreq(str, n):
for i in range(n):
freq[str[i]] += 1
# function iterates through the encoded string s
# if s[i]=='1' then move to node->right
# if s[i]=='0' then move to node->left
# if leaf node append the node->data to our output string
def decode_file(root, s):
ans = ""
curr = root
n = len(s)
for i in range(n):
if s[i] == '0':
curr = curr.left
else:
curr = curr.right
# reached leaf node
if curr.left is None and curr.right is None:
ans += curr.data
curr = root
return ans + '\0'
# Driver code
if __name__ == "__main__":
minHeap = []
str = "ShandyDemo"
encodedString, decodedString = "", ""
calcFreq(str, len(str))
HuffmanCodes(len(str))
print("Character With there Frequencies:")
for key in sorted(codes):
print(key, codes[key])
for i in str:
encodedString += codes[i]
print("\nEncoded Huffman data:")
print(encodedString)
# Function call
decodedString = decode_file(minHeap[0], encodedString)
print("\nDecoded Huffman Data:")
print(decodedString)
Easy Problems
1. Fractional Knapsack
Given two arrays, val[] and wt[], representing the values and weights of item respectively, and an integer capacity representing the maximum weight a knapsack can hold, we have to determine the maximum total value that can be achieved by putting the items in the knapsack without exceeding its capacity. Items can also be taken in fractional parts if required.
Examples:
1
2
3
4
5
6
7
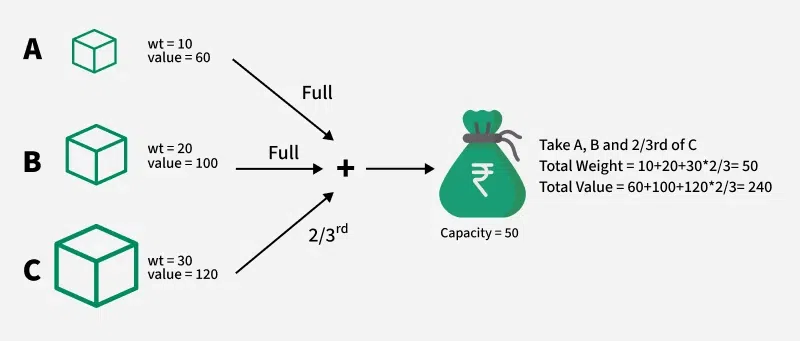
Input: val[] = [60, 100, 120], wt[] = [10, 20, 30], capacity = 50
Output: 240
Explanation: We will take the items of weight 10kg and 20kg and 2/3 fraction of 30kg.
Hence total value will be 60 + 100 + (2/3) * 120 = 240.
Input: val[] = [500], wt[] = [30], capacity = 10
Output: 166.667
Case 1: Picking the items with smaller weights first Example: val[] = [10, 10, 10, 100], wt[] = [10, 10, 10, 30], capacity = 30
- If we start picking smaller weights, we can pick the three items of weight 10 → total value = 10+10+10 = 30.
- But the optimal choice is to take the last item (value 100, weight 30) → total value = 100.
So, choosing smaller weights first fails here.
Case 2: Picking items with larger value first Example: val[]= [10, 10, 10, 20], wt[] = [10, 10, 10, 30], capacity = 30
- If we start picking higher values, we might choose the last item (value 20, weight 30) → total value = 20.
- But the better choice is to take the three items of weight 10 each → total value = 10+10+10 = 30.
So, choosing higher values first also fails.
Steps to solve the problem:
- Calculate the ratio (value/weight) for each item.
- Sort all the items in decreasing order of the ratio.
- Iterate through items:
- if the current item fully fits, add its full value and decrease capacity
- otherwise, take the fractional part that fits and add proportional value.
- Stop once the capacity becomes zero.
Code demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
def compare(a, b):
a1 = (1.0 * a[0]) / a[1]
b1 = (1.0 * b[0]) / b[1]
return b1 - a1
def fractionalKnapsack(val, wt, capacity):
n = len(val)
# Create list to store value and weight
# items[i][0] = value, items[i][1] = weight
items = [[val[i], wt[i]] for i in range(n)]
# Sort items based on value-to-weight ratio in descending order
items.sort(key=lambda x: x[0]/x[1], reverse=True)
res = 0.0
currentCapacity = capacity
# Process items in sorted order
for i in range(n):
# If we can take the entire item
if items[i][1] <= currentCapacity:
res += items[i][0]
currentCapacity -= items[i][1]
# Otherwise take a fraction of the item
else:
res += (1.0 * items[i][0] / items[i][1]) * currentCapacity
# Knapsack is full
break
return res
if __name__ == "__main__":
val = [60, 100, 120]
wt = [10, 20, 30]
capacity = 50
print(fractionalKnapsack(val, wt, capacity))
2. Minimum cost to make array size 1 by removing larger of pairs
Given an array of n integers. We need to reduce size of array to one. We are allowed to select a pair of integers and remove the larger one of these two. This decreases the array size by 1. Cost of this operation is equal to value of smallest one. Find out minimum sum of costs of operations needed to convert the array into a single element.
**Examples: **
1
2
3
4
5
6
7
Input: arr[]= [4 ,3 ,2 ]
Output: 4
Explanation: Choose (4, 2) so 4 is removed, new array = {2, 3}. Now choose (2, 3) so 3 is removed. So total cost = 2 + 2 = 4.
Input: arr[]=[ 3, 4 ]
Output: 3
Explanation: choose (3, 4) so cost is 3.
The idea is to always pick the minimum value as part of the pair and remove larger value. This minimizes cost of reducing array to size 1.
Code demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Python program to find minimum
# cost to reduce array size to 1
# function to calculate the
# minimum cost
def cost(a, n):
# Minimum cost is n-1 multiplied
# with minimum element.
return ( (n - 1) * min(a) )
# driver code
a = [ 4, 3, 2 ]
n = len(a)
print(cost(a, n))
# This code is contributed by
# Smitha Dinesh Semwal
3. Minimum rotations to unlock a circular lock
You are given a lock which is made up of n-different circular rings and each ring has 0-9 digit printed serially on it. Initially all n-rings together show a n-digit integer but there is particular code only which can open the lock. You can rotate each ring any number of time in either direction. You have to find the minimum number of rotation done on rings of lock to open the lock.
Examples:
1
2
3
4
5
6
7
8
9
10
11
12
13
Input : Input = 2345, Unlock code = 5432
Output : Rotations required = 8
Explanation : 1st ring is rotated thrice as 2->3->4->5
2nd ring is rotated once as 3->4
3rd ring is rotated once as 4->3
4th ring is rotated thrice as 5->4->3->2
Input : Input = 1919, Unlock code = 0000
Output : Rotations required = 4
Explanation : 1st ring is rotated once as 1->0
2nd ring is rotated once as 9->0
3rd ring is rotated once as 1->0
4th ring is rotated once as 9->0
For a single ring we can rotate it in any of two direction forward or backward as:
- 0->1->2….->9->0
- 9->8->….0->9
But we are concerned with minimum number of rotation required so we should choose min (abs(a-b), 10-abs(a-b)) as a-b denotes the number of forward rotation and 10-abs(a-b) denotes the number of backward rotation for a ring to rotate from a to b. Further we have to find minimum number for each ring that is for each digit. So starting from right most digit we can easily the find minimum number of rotation required for each ring and end up at left most digit.
Code demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# Python3 program for min rotation to unlock
# function for min rotation
def minRotation(input, unlock_code):
rotation = 0;
# iterate till input and unlock
# code become 0
while (input > 0 or unlock_code > 0):
# input and unlock last digit
# as reminder
input_digit = input % 10;
code_digit = unlock_code % 10;
# find min rotation
rotation += min(abs(input_digit - code_digit),
10 - abs(input_digit - code_digit));
# update code and input
input = int(input / 10);
unlock_code = int(unlock_code / 10);
return rotation;
# Driver Code
input = 28756;
unlock_code = 98234;
print("Minimum Rotation =",
minRotation(input, unlock_code));